世界杯官方认证平台 ICML 2026|OFA-TAD迈向one-for-all通用相等检测新范式


表格相等检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精确识别显耀偏离平方分散的珍稀样本,其在医疗会诊、金融风控及集结安全等重要领域的数据挖掘与安全保险任务中阐扬着中枢作用。
然则,现时大大都 TAD 治安仍然受命一种 one-for-one(OFO)范式:每来一个新数据集,就要重新磨练一个专属检测器,致使重新调参、重新选拔预处理形势。这不仅带来腾贵的缱绻和运维本钱,也让模子难以泛化到未知领域。
那么,表格相等检测能否像大模子相同,磨练一次,就能移动到不同领域的数据表上,终了信得过的 one-for-all(OFA)?
近期,来自 Griffith University 和 Tongji University 的团队建议了 OFA-TAD,迈出了通用表格相等检测的迫切一步。该治安将 TAD 从传统的 one-for-one(OFO)激动到 one-for-all(OFA)范式:模子只需在多个源数据集上磨练一次,便可胜利移动到未见过的标的数据集,无需标的域微调或重新磨练。
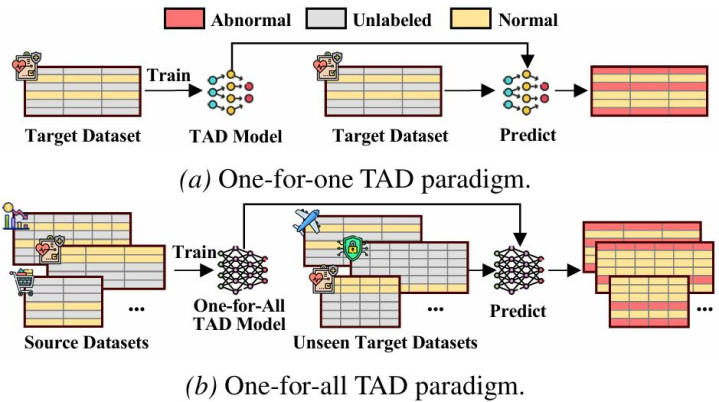
图注:传统 OFO 范式与 OFA-TAD 所追求的 OFA 范式对比。
开云体育KaiYunSports中国官网
论文标题:Towards One-for-All Anomaly Detection for Tabular Data
论文地址:https://arxiv.org/abs/2603.14407
代码地址:https://github.com/Shiy-Li/OFA-TAD
从 one-for-one 到 one-for-all:
表格相等检测的新问题
传统 TAD 治安通常在单个数据集内磨练和测试。不管是经典的 Isolation Forest、LOF、KNN,已经频年来的 AutoEncoder、DeepSVDD、MCM、DRL、DisentAD 等深度治安,它们大多默许每个数据集都有我方的磨练历程。
这种范式在单一数据集上可能阐扬可以,但在果然部署中会碰到两个中枢问题:
磨练本钱高:每个新场景都需要重新磨练检测器,通常还追随超参数搜索和预处理选拔。
泛化材干弱:模子容易依赖某个数据集的局部模式,一朝移动到新领域,性能可能彰着下落。
OFA-TAD 试图恢复一个更具挑战性的问题:能否磨练一个通用的表格相等检测器,在濒临来自医疗、金融、图像特征、集结安全等不同领域的新数据表时,仍然概况即插即用地发现相等?
这一问题并不浅薄。表格数据自然存在「语义鸿沟」:不同数据集的特征维度、特征含义和数值分散都可能十足不同。医疗数据中的相等可能是相等血压或心率,金融数据中的相等则可能是相等往复金额或账户行径。胜利对皆原始特征语义,险些不行行。
重要洞见:相等的共性
不在特征语义,而在邻域距离
OFA-TAD 的中枢洞见是:跨领域可移动的相等信号,不应依赖具体特征含义,而应来自更通用的邻域结构。
不管是相等病东谈主记载、诈骗往复,已经相等集结行径,它们通常都有一个共同点:相关于平方样本,它们更「孑然」,也便是与局部邻居的距离模式更不寻常。
因此,OFA-TAD 不胜利学习原始表格特征,而是将每个样本暗示为其 Top-K 隔壁距离序列,即「邻居距离画像」。这种暗示具有两个上风:
语义无关:不依赖具体列名或领域含义,不同维度的数据表也能被振荡为固定长度的距离序列。
相等敏锐:相等样本通常会在隔壁距离弧线上阐扬出更彰着的跳变、长尾或孑然特征。
换句话说,OFA-TAD 将不同领域的数据表,和洽瞥化为一种可相比的「距离言语」。
多视角距离编码:
让模子自动顺应不同数据变换
仅使用一种距离空间仍然不够。表格数据对预处理形势高度敏锐:表率化、归一化、分位数变换等操作,都会改革样本之间的邻域相关。某些相等在表率化空间中更彰着,另一些相等可能在 MinMax 或 Quantile 空间中更容易被发现。
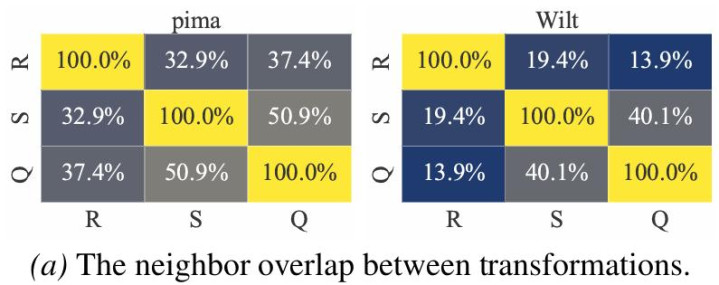
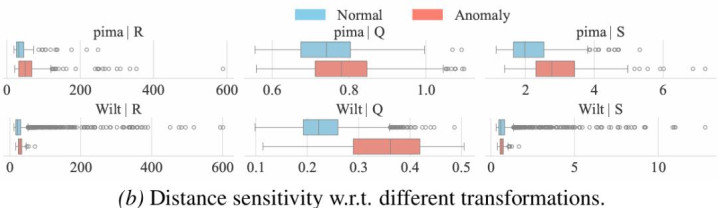
图注:不同特征变换会显耀改革隔壁结构与相等可分性。R:Raw,S:Standardized,and Q:Quantile。
为了处理这一问题,OFA-TAD 构建了多个由不同特征变换领导的度量空间,举例 Raw、Standardized、MinMax、Quantile 等。关于统一个样本,模子会在每个视角下索要 Top-K 邻居距离序列,并通过分位数归一化将不同数据靠拢的距离模范映射到和洽范围。
这么,世界杯官方认证平台OFA-TAD 既幸免了对某一种预处理形势的依赖,也能拿获互补的相等字据。
MoE 自顺应交融:
让每个样本选拔最可靠的距离视角
不同视角并非同等可靠。若是浅薄拼接或平均多个距离视角,反而可能让强信号被弱视角稀释。
为此,OFA-TAD 进一步引入了 Mixture-of-Experts(MoE)评分集结:
视角众人:每个众人认真一个特定距离视角,诈欺位置编码和防护力池化建模 Top-K 邻居距离序列,并输出该视角下的相均分数。
门控集结:根据不同视角的表征,动态臆测每个众人的权重。
加权交融:模子根据样本自己特色,自顺应强调最有效的视角,拦截噪声视角,得到最终相均分数。
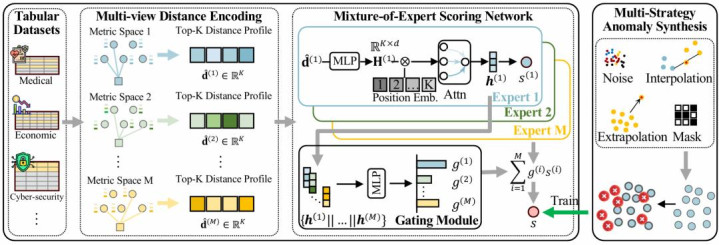
图注:OFA-TAD 的举座框架:多视角距离编码、MoE 自顺应评分,以及多计谋伪相等合成。
这种联想使得 OFA-TAD 不需要提前知谈某个标的数据集最合乎哪种预处理形势,而是能在推理时自动选拔更可靠的距离字据。
莫得果然相等标签何如办?
多计谋合成伪相等
表格相等检测通常处于 one-class setting:磨练阶段只须平方样本,果然相等极少致使十足不行见。为了在不破裂这一设定的前提下提供监督信号,OFA-TAD 联想了多计谋伪相等合成机制。
具体而言,模子通过四类形势生成千般化的伪相等:
流形外推:模拟远隔平方数据流形的全局相等。
簇间插值:模拟落在低密度区域的局部相等。
噪声注入:模拟测量弊端或赶快扰动。
特征脱色:模拟数据缺失或特征损坏。
这些伪相等与平方样本共同组成磨练信号,匡助模子学习更老成、可移动的相等有商量领域。
实践效用:34 个数据集、
14 个领域上的通用检测材干
实践中,OFA-TAD 在 7 个源数据集上磨练一次,并在 34 个来自 14 个领域的数据集上进行评测。与之对比的 9 个代表性基线治安,包括经典治安 IForest、LOF、KNN,以及深度治安 AE、DeepSVDD、LUNAR、MCM、DRL、DisentAD。
值得防护的是,对比治安按照传统 OFO 范式在每个标的数据集上诀别磨练,而 OFA-TAD 不在标的数据集上重新磨练或微调,仅使用标的数据集的平方磨练样本行动推理时的荆棘文,用于隔壁检索和距离归一化,况兼使用固定的交流一组超参数在通盘标的数据集上进行测试。
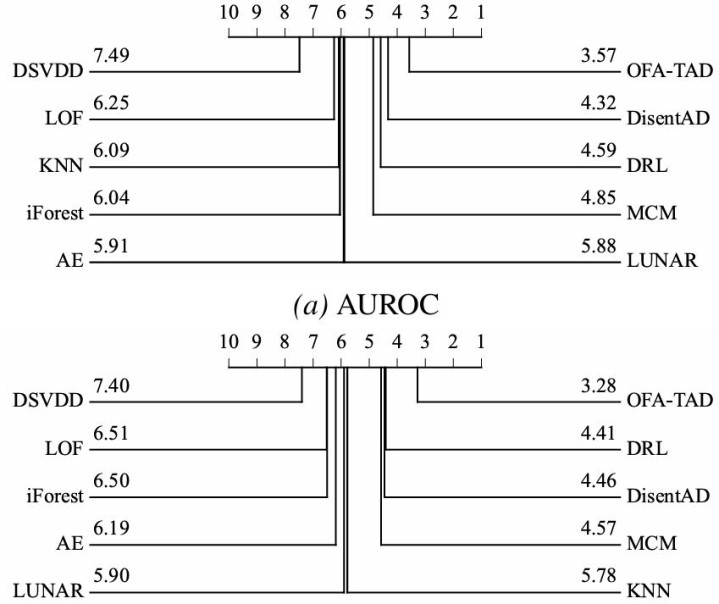
1)举座性能:一次磨练,跨 34 个数据集踏实向上
在这一更严格的成就下,OFA-TAD 仍然赢得了最优的举座阐扬。如下图所示,它在 AUROC、AUPRC 等见解上的平均排行均保捏向上。
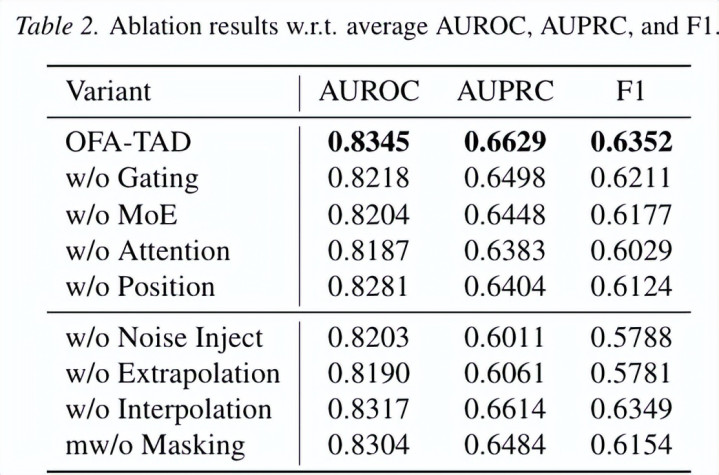
2)消融实践:多视角、MoE 与防护力不行偏废
消融实践进一步考证了各模块的迫切性。如下图所示,去掉门控交融、MoE 众人、防护力池化或位置编码都会带来性能下落,其中防护力池化的影响尤为彰着,讲解对邻居距离字据进行自顺应加权,是拿获寥落相等信号的重要。
同期,多计谋伪相等合成也提供了互补监督信号。移除自便一种合成计谋都会酿成性能下落,讲解果然相等的花式复杂千般,需要通过多种伪相等模式共同描述。
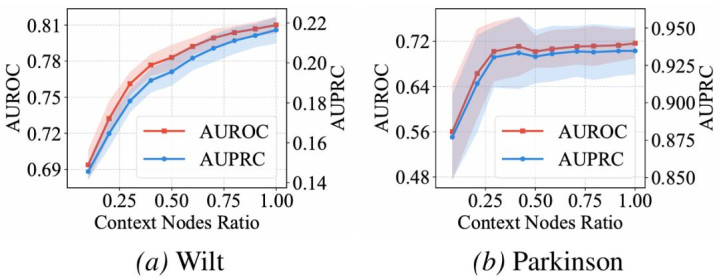
3)荆棘文鲁棒性:极少平方样本也能相沿即时推理
OFA-TAD 还展现出细致的荆棘文鲁棒性。即使标的数据靠拢只须一小部分平方样本可行动荆棘文,模子仍能进行踏实的即时推理;跟着荆棘文样本增多,性能进一步擢升并逐渐趋于充足。
这标明 OFA-TAD 可以在有限的平方样本下快速成就标的域邻域结构,从而完成 on-the-fly 相等检测。
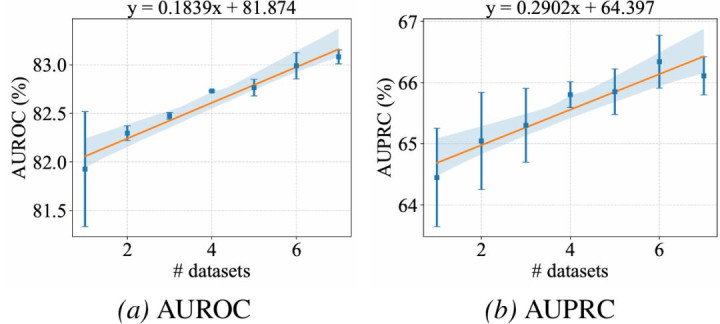
4)dataset-specific scaling
更进一步,跟着源数据集数目增多,OFA-TAD 的移动性能呈现踏实擢升趋势。这讲解通用表格相等检测具备访佛「dataset-specific scaling」的后劲:预磨练数据越丰富,模子越可能学到跨领域的相等检测法例。
回想:迈向通用表格相等检测器
OFA-TAD 为表格相等检测从 one-for-one 向 one-for-all 范式调度提供了一个初步的尝试,并在无需标的域微调的跨域移动场景下展现出了极具后劲的性能。
改日,通用表格相等检测仍有庞大的探索空间。通过引入更大领域的预磨练数据集、联想更先进的磨练治安,以及更深度的荆棘文信息诈欺,通用 TAD 模子有望进一步缩小工业部署本钱世界杯官方认证平台,为医疗、金融、安全等高价值场景提供愈加无邪可靠的相等检测基础景观。